





.png?width=1920&height=1080&name=Consulting2_Menu_1%20(1).png)








Article
Balancing privacy and innovation: Data de-identification and redaction in Healthcare

Sana Pathan
Sr. Practice Architect, CitiusTech
05-Feb-2026
Share:
Introduction
Healthcare organizations are increasingly leveraging data analytics, artificial intelligence (AI), and Interoperability to improve patient outcomes and operational efficiency. Clinical data underpin these efforts, enabling the tracking of disease progression, the evaluation of treatment efficacy, and the delivery of personalized care. However, much of this data contains sensitive information such as Protected Health Information (PHI) and Personally Identifiable Information (PII), which must be handled in strict compliance with privacy regulations like the Health Insurance Portability and Accountability Act (HIPAA) and the General Data Protection Regulation (GDPR).
This article focuses on the critical role of data redaction and de-identification in safeguarding patient privacy while maintaining the utility of healthcare data. It explains the differences between these methods, explores why they matter for compliance and innovation, and outlines practical strategies for implementation. By doing so, it aims to guide healthcare organizations in balancing innovation with compliance and ethical responsibility.
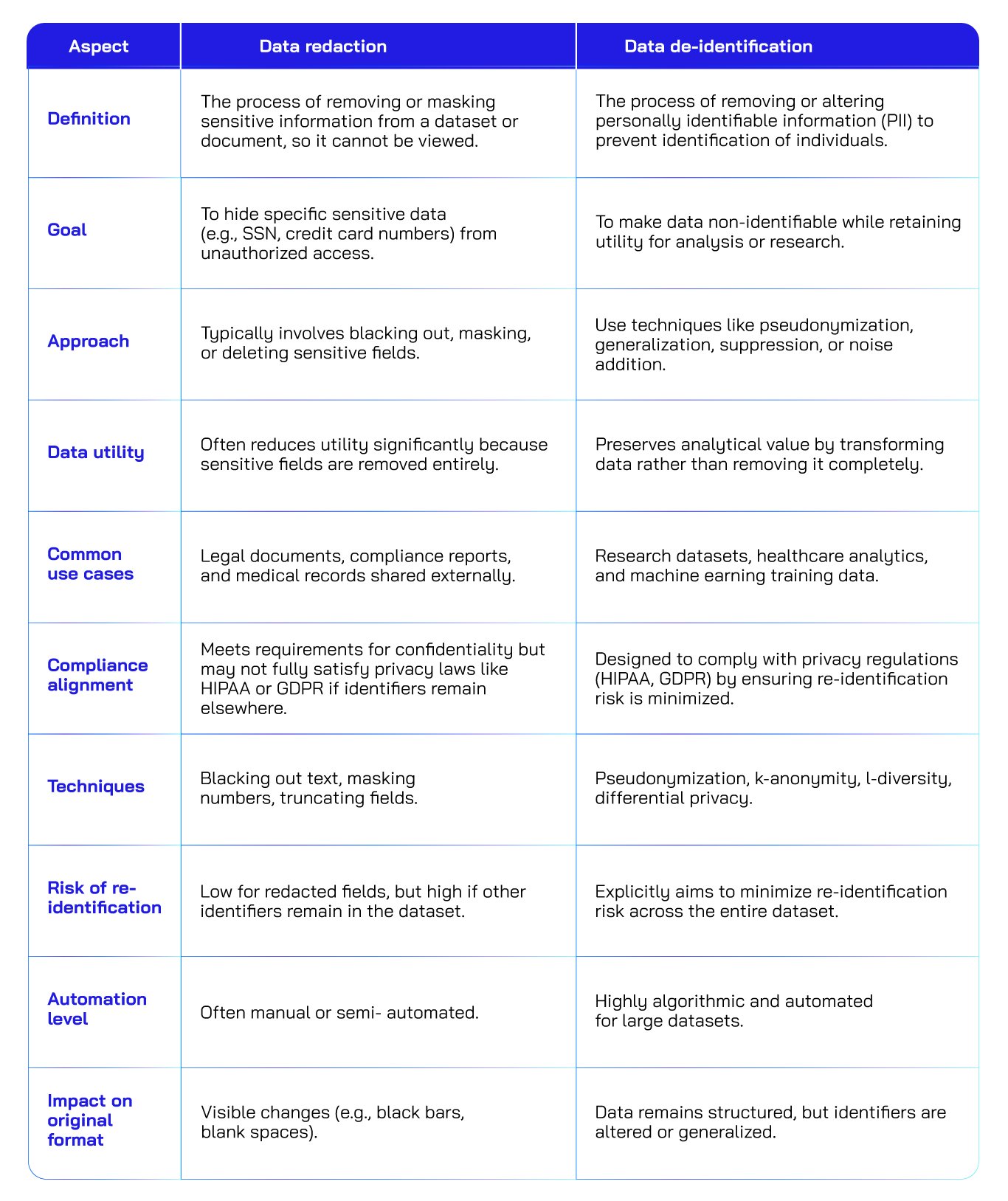
Data redaction vs data de-identification: A quick comparison
Regulatory frameworks to consider
When implementing data redaction or de-identification, healthcare organizations must align with established privacy regulations and standards. These frameworks set the rules for what constitutes compliant data handling:
● HIPAA privacy rule
HIPAA outlines two methods for de-identification:
- Safe Harbor: Refers to the removal of 18 specific identifiers. Organizations use this method when they want to share health data for research, analytics, or public health purposes, or when they do not have access to a qualified expert for the alternative method (Expert Determination).
The following are the 18 identifiers defined under this method:
- Names
- Geographic subdivisions smaller than a state (e.g., street address, city, ZIP code – except first 3 digits if population > 20,000)
- All elements of dates (except year) directly related to an individual (e.g., birth date, admission/discharge dates)
- Telephone numbers
- Fax numbers
- Email addresses
- Social Security numbers
- Medical record numbers
- Health plan beneficiary numbers
- Account numbers
- Certificate/license numbers
- Vehicle identifiers and serial numbers
- Device identifiers and serial numbers
- Web URLs
- IP addresses
- Biometric identifiers (e.g., fingerprints, voiceprints)
- Full-face photographs and comparable images
- Any other unique identifying number, characteristic, or code
- Additionally, the entity must not have actual knowledge that the remaining information could be used to identify the individual
- Expert determination: A qualified expert certifies that the risk of re-identification is very small.
● GDPR and global standards
GDPR focuses primarily on EU Data Privacy, emphasizing key features such as redaction for Subject Access Requests (SARs), data minimization, and breach prevention.
In addition, ISO 27038 Global Standard is especially relevant for organizations that must comply with GDPR, HIPAA, NIST, and other privacy laws. It defines Redaction as the permanent, irreversible removal of sensitive data from electronic documents. Key requirements:
- Irreversibility: Data must be unrecoverable.
- Audit logging: Every redaction action must be timestamped and documented.
- Metadata removal: Hidden data must be eliminated.
- Tool validation: Redaction software must meet strict testing criteria
Waivers or exceptions
Under HIPAA and related healthcare data standards, waivers or exceptions to de-identification/redaction requirements are allowed in specific, regulated circumstances.
- Waiver of authorization for research
HIPAA permits use or disclosure of Protected Health Information (PHI) without patient authorization for research purposes if:
- An Institutional Review Board (IRB) or Privacy Board grants a waiver of authorization.
- The waiver must document:
- The research poses minimal risk to privacy.
- The waiver is necessary for the research.
- There are adequate safeguards in place.
- Limited data sets with data use agreements
HIPAA allows sharing of limited data sets (which may include some identifiers like dates and city) without full de-identification, if:
- A Data Use Agreement (DUA) is in place.
- The DUA restricts how the data can be used and prohibits re-identification.
- This is useful for research, public health, and healthcare operations.
- Preparatory to research activities
PHI may be accessed without de-identification to:
- Prepare a research protocol.
- Identify potential study participants.
However, the data cannot be removed from the covered entity, and no actual research can be conducted at this stage. - Expert determination method
Instead of redacting all identifiers (Safe Harbor method), HIPAA allows PHI to be considered de-identified if:
- A qualified expert determines that the risk of re-identification is very small.
- The expert must document the methods and results used to reach this conclusion.
This method is often used in advanced analytics, AI model training, and large-scale data sharing.
Key techniques in practice
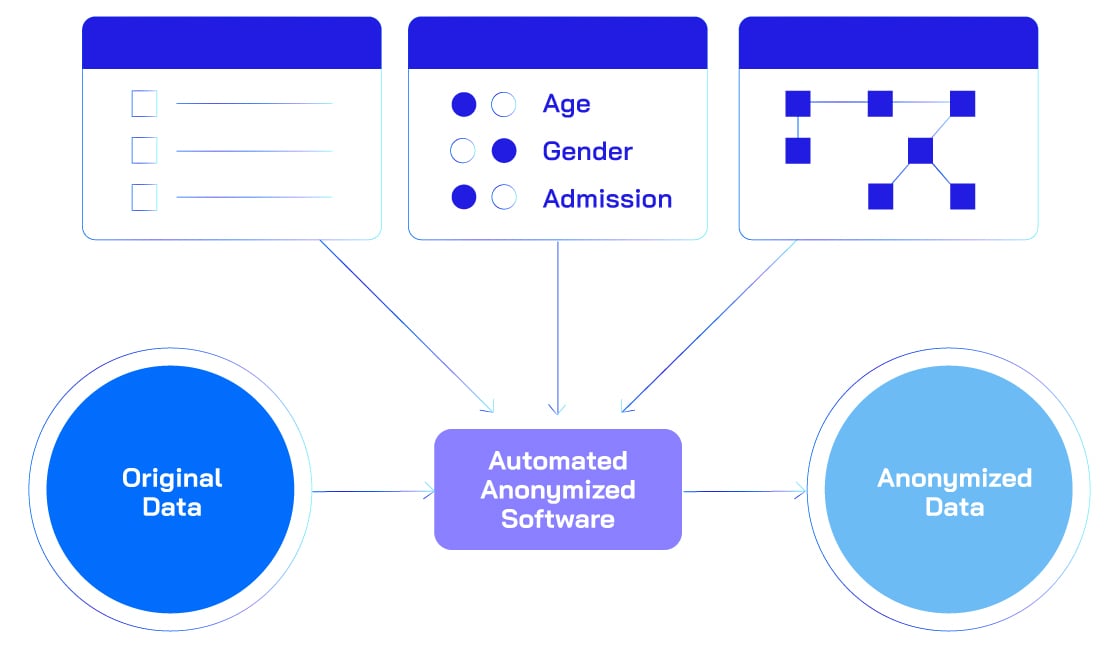
- De-identification techniques
- Anonymization: Irreversible removal of identifiers.
Ensures that individuals cannot be re-identified, even when combined with external datasets.
- Pseudonymization: Replacement with artificial identifiers.
Original identifiers are substituted with tokens or codes, enabling internal linkage but preventing direct identification.
- Generalization: Broadening data granularity (e.g., age ranges).
Converts precise values into broader categories to reduce uniqueness while maintaining analytical relevance.
- Suppression: Removing high-risk data points.
Entire fields or records that pose a high re-identification risk are omitted from the dataset.
- Perturbation: Adding noise to data.
Introduces small random changes to obscure exact values while preserving overall statistical patterns.
- Tokenization and Hashing: Replacing identifiers with secure tokens.
Converts sensitive identifiers into cryptographically secure tokens or hashes, making reversal computationally infeasible.
- Anonymization: Irreversible removal of identifiers.
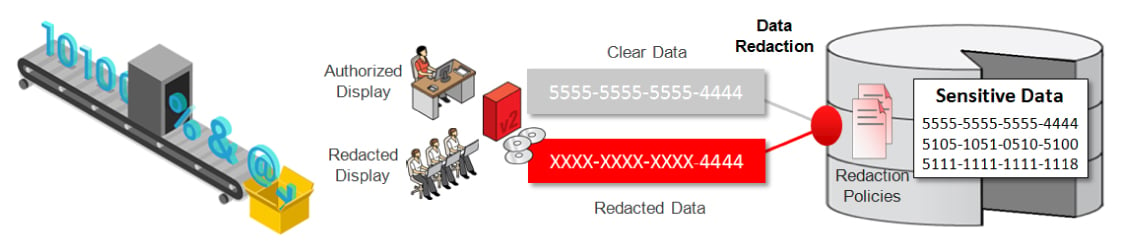
- Redaction methods
- Text Redaction: Masking PHI in clinical notes.
Removes or masks sensitive text like patient names and IDs in clinical notes.
- Image Redaction: Removing burnt-in text and facial features.
Eliminates burnt-in identifiers and facial features from medical images, documents, or reports.
- Video Redaction: Blurs faces and visible identifiers in recorded healthcare footage.
Ensures that individuals cannot be visually identified in video records.
- Text Redaction: Masking PHI in clinical notes.
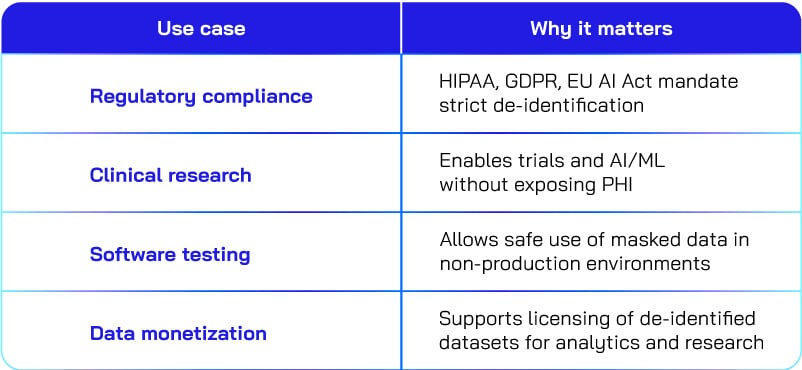
Real-world applications of privacy techniques
From ensuring regulatory compliance to enabling AI-driven research, data redaction and data de-identification techniques help organizations use data responsibly without compromising patient privacy. The table below highlights key use cases and why they matter.
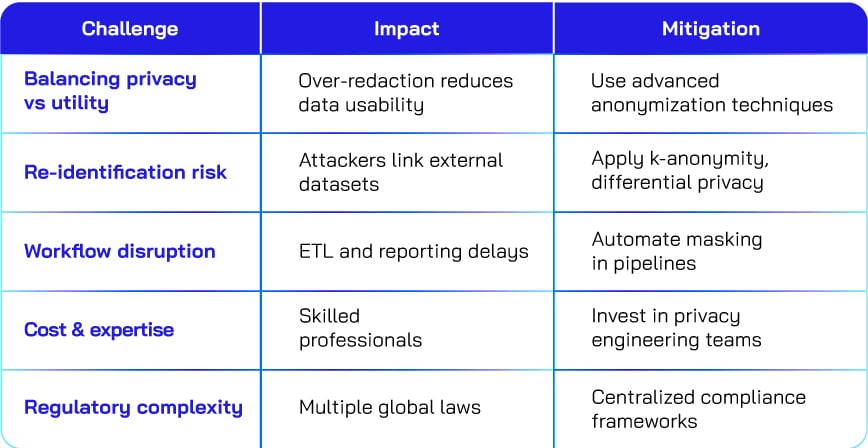
Challenges and how to overcome them
Implementing data redaction and de-identification is not without hurdles. Organizations often struggle with balancing privacy and data utility, mitigating re-identification risks, and managing workflow disruptions. The table below outlines common challenges, their impact, and practical strategies to address them.
Use-case based recommendations for data privacy
- Radiology
- Recommendation: Use de-identification (pseudonymization + generalization) for DICOM images to retain clinical details while removing patient identifiers.
- Why: Redaction would strip metadata needed for AI imaging models and interoperability.
- Life Sciences research
- Recommendation: Apply anonymization or perturbation for genomic data to prevent re-identification while enabling population-level studies.
- Why: Genetic data is highly sensitive and unique, requiring irreversible techniques.
- EHR/EMR systems
- Recommendation: Use pseudonymization for patient IDs and suppression for rare conditions or outliers.
- Why: Maintains longitudinal tracking for care coordination without exposing identity.
- Lab results
- Recommendation: Implement tokenization and hashing for patient identifiers and generalization for age or location data.
- Why: Ensures privacy while preserving analytical value for clinical decision support.
- Clinical trials
- Recommendation: Combine pseudonymization with perturbation for sensitive attributes like dates and addresses.
- Why: Allows researchers to analyze trends without compromising participant confidentiality.
Conclusion
Data redaction and de-identification are crucial for ensuring the ethical and compliant use of data in healthcare IT. For organizations focused on Healthcare IT, these practices enable innovation while preserving patient trust. By adopting robust frameworks and technologies, healthcare providers can unlock the full potential of data-driven care.


















































.webp?width=400&height=400&name=The%20future%20of%20Healthcare%20(1).webp)




















.png?width=400&height=400&name=7-Jun-13-2025-02-27-19-6568-PM%20(1).png)























