





.png?width=1920&height=1080&name=Consulting2_Menu_1%20(1).png)








Article
Think beyond monitoring
Can embracing observability lead to reliable healthcare systems?

Jeevan Jadhav
Sr. Tech Specialist,
Performance Testing Practice Lead,
CitiusTech

Seema Pawar
Technical Lead,
Quality & Performance Practice,
CitiusTech
03-Apr-2024
Share:
Large-scale healthcare organizations (HCOs) with extensive workflows must ensure round-the-clock availability, reliability, and resilience. With the health app revenue touted to be valued at $35.7 billion by 2030[1], healthcare enterprises must prioritize qualitative measures to ensure complete and comprehensive visibility of their digital service estate. Through Site Reliability Engineering (SRE), HCOs can continuously monitor their advanced systems and applications and perform code fixes whenever problems arise.
Observability is a key element under SRE and is crucial for screening the performance of complex health systems. It helps engineers identify application issues along with root cause analysis. SRE teams can venture beyond standard monitoring practices with observability, conducting quick diagnosis and resolution and expediting go-to-market rates – leading to safer and more valuable products for customers.
The advantage of observability in digital health ecosystems
Healthcare systems and services require high levels of safety and reliability because they handle sensitive patient data and facilitate critical healthcare procedures. SRE teams build and maintain a robust infrastructure, automating repetitive activities/tasks, and ensuring these systems and services run smoothly. They strategize on error budgeting, observability, and incident response to achieve optimal system dependability. SRE promotes a collaborative culture between development and operations – emphasizing the significance of balancing innovation with system stability while ensuring the durability and efficiency of complex digital ecosystems.
The current discussion over monitoring vs observability concerns a fundamental distinction: "What" vs "Why." In the context domain, observability provides a more comprehensive view of system failures than surface-level information obtained from monitoring. A recent study cites that over 30%[2] of enterprises will have adopted observability techniques to improve their digital business services performance. This only adds to its growing relevance as more and more businesses realize the ability to respond to outages and performance lapses of their digital solutions complemented by skilled professionals and a thorough understanding of corrective measures.
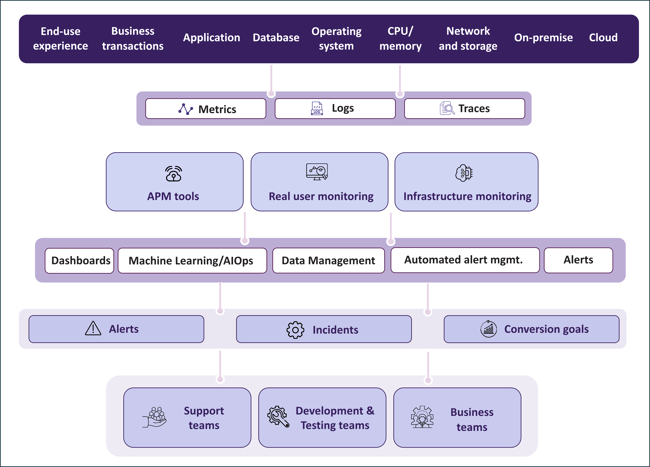
Fig 1: Holistic view of observability strategy
Healthcare companies can achieve observability with three key practices:


















































.webp?width=400&height=400&name=The%20future%20of%20Healthcare%20(1).webp)




















.png?width=400&height=400&name=7-Jun-13-2025-02-27-19-6568-PM%20(1).png)























